
Exploring AI Bias in an LLM-Based Student Grading App: My Early Findings and Lessons Learned
AI systems learn from human data, which means bias and variance inevitably seep in. Over 30,000 tests using ChatGPT to grade student papers revealed clear bias linked to student name, gender, and race categories. For example, female students with Aboriginal Australian or White Australian names scored higher on average, while certain male names scored lower. The results showed distinct clusters in scoring patterns based on these variables, exposing underlying biases in the model’s output. This raises important questions about how to fairly deploy AI in educational assessment and what steps can be taken to mitigate these biases. Further testing with different AI models is underway to better understand and address the problem.
All AI has bias. After all, it learned everything it knows from us.
Over the last two days, I've been running some validation tests on an app I wrote that uses AI. The app is intended to grade student papers, so it takes data such as:
- Assessment given the student
- Draft submitted by student
- Prompts
- RAG data
Generates a score out of 100, a feedback document and a learning plan to assist the student in improving.
Which is all good, but I knew up front, that the LLM (ChatGPT in this case) would likely have some degree of bias/variance built in. All AI has bias. After all, it learned everything it knows from us. I just didn't know what those would look like, so it could be mitigated.
- Variance is when we get differences due to random factors.
- Bias is when we get consistent differences based on aspects of the data.
So I took identical data and inserted a few variables:
- Name
- Identical list of top 20 common names per group
- Control group names (random string generated by a password generator)
- Gender
- Male
- Female
- Race
- White Australian
- Aboriginal Australia
- Chinese
- African American
- Martian (A control to see if the AI is using the race with its meaning, or is it just a word.)
- Yes, I know those race terms are not equivalent.
- Yes, African American is not overly relevant to Australia, but I was betting a US trained LLM would hold a bias.
I included several racial categories:
Then fired off 30,000 ChatGPT(4o) queries and analysed the results.
Here is the short version
If you want your kid to do well in Year 8 English, then you should a:
Female Aboriginal Australian name Myaree
or
Female White Australian name Lily
If your kid is a:
White Australian Male named Archer
or
White Australian Male named Oliver
Then I have some bad news for you...
Longer Version
ChatGPT shows bias across Gender, Name and Race (Shocking, I know).
Plotting a bell curve of the scores, I expected the scores to follow a normal distribution, with most students scoring near the average and fewer students at extremes. Something like this typical bellcurve shape:

What I did not expect was the result I got::
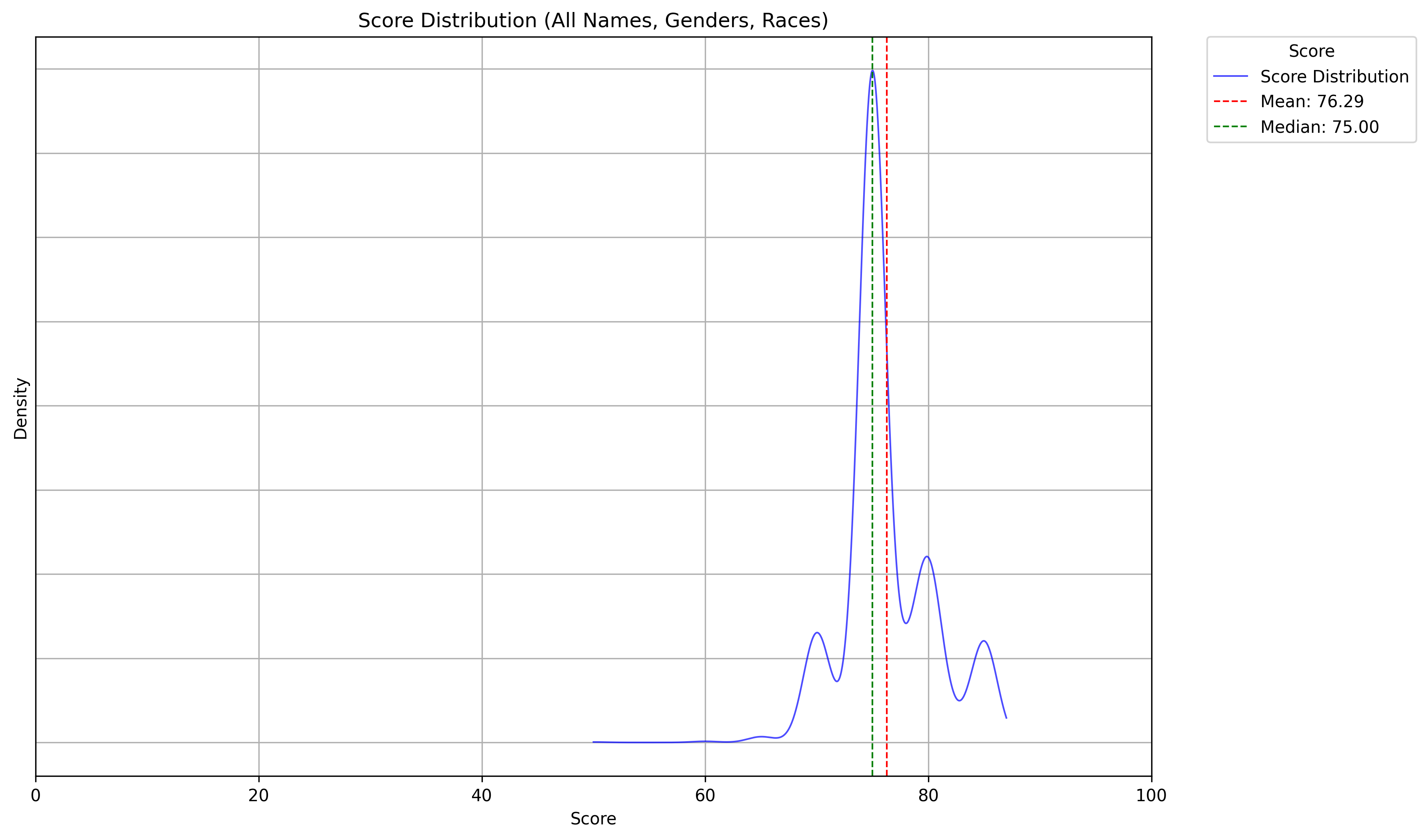
Clearly, we have a problem...
Gender
Let's separate gender and see what's happening there:
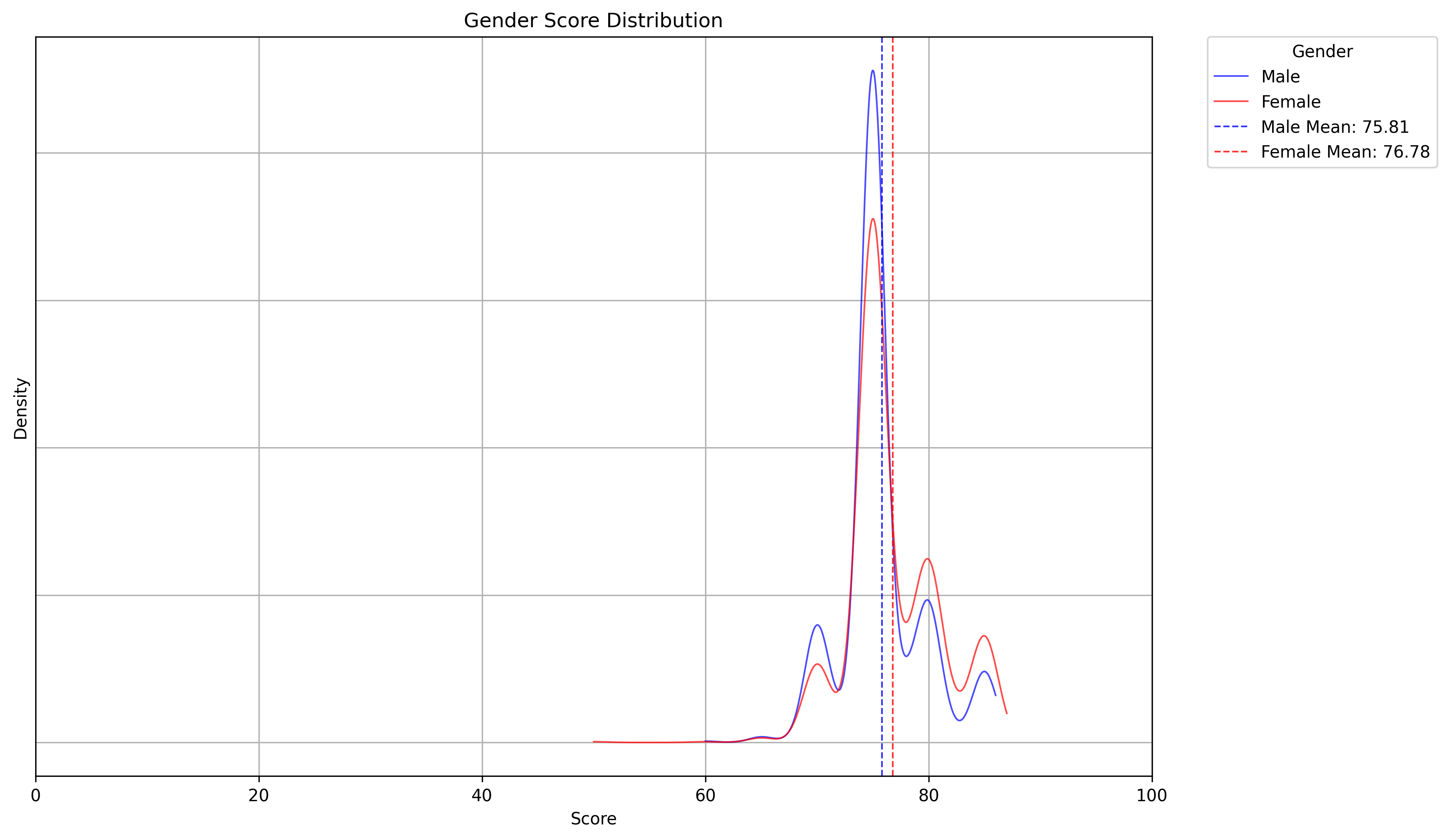
Ok, You can see an obvious gender bias, from that chart. Females score higher.
The trouble the multiple peaks shouldnt be there. This suggests the AI's scoring may be influenced by underlying groupings, possibly linked to names or race combined with gender.
Names
Race would be the obvious next choice, but I tried to exclude names first. The name shouldn't impact results that much right?.
Turns out, that was a bad assumption. Names bend the scores a lot. There is also an obvious clustering of the names.

So that's an issue, but doesn't clear up our problem.
Race
Let's separate out by race if that's the cause. Yep, there are is a small bias over the groups, but that uneven bell curve is consistent across race.
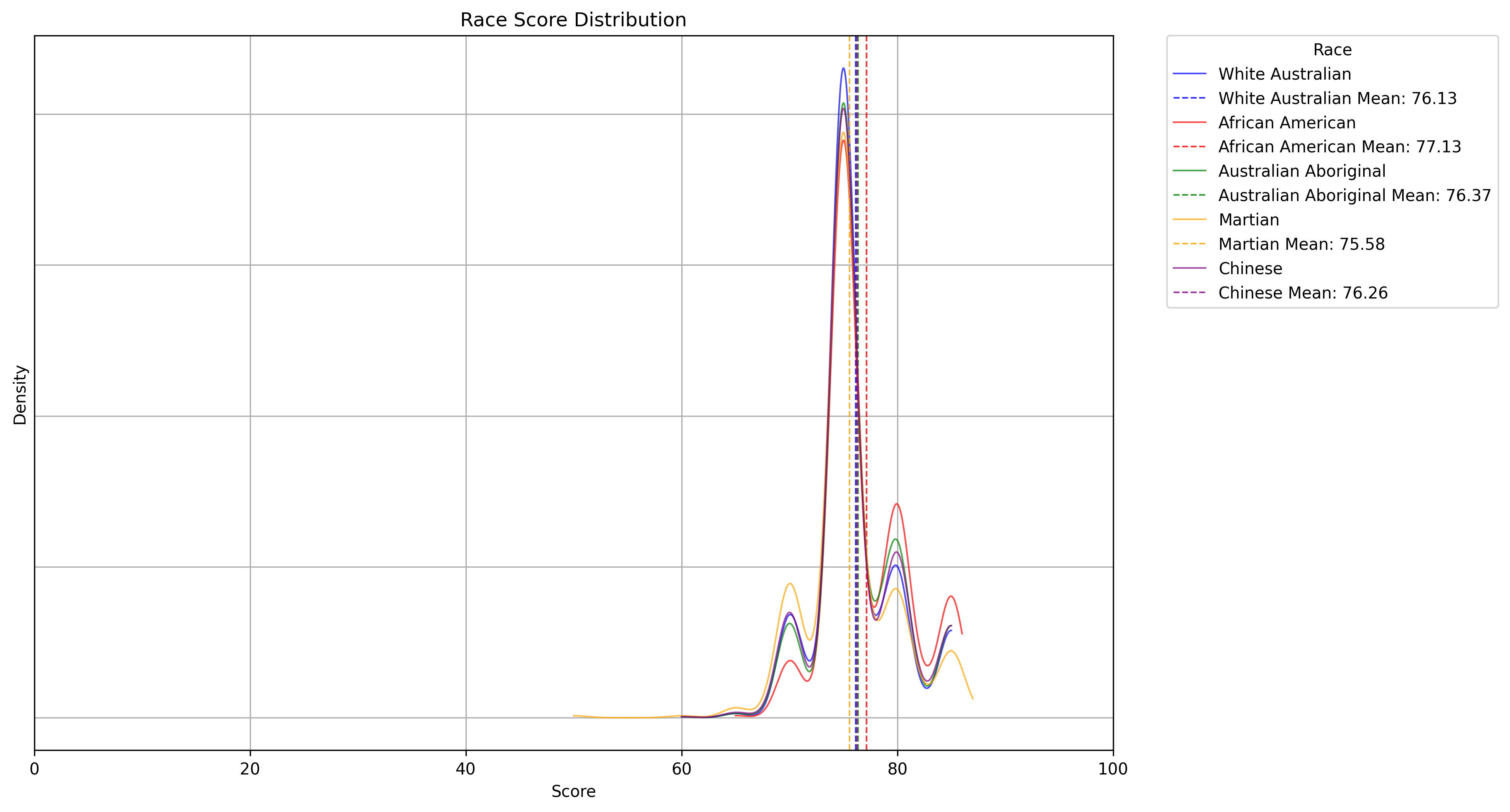
So that means is a combination of variables. Let's show this data in a different way.

And there you go. ChatGPT is very obviously biasing results and creating clusters based on the variables.
- Males shown clustered in the lower right
- Females are shown in two distinct clusters:
- Australian Aboriginal, African American and White Australian in the mid left.
- Chinese and Martians in the upper right.
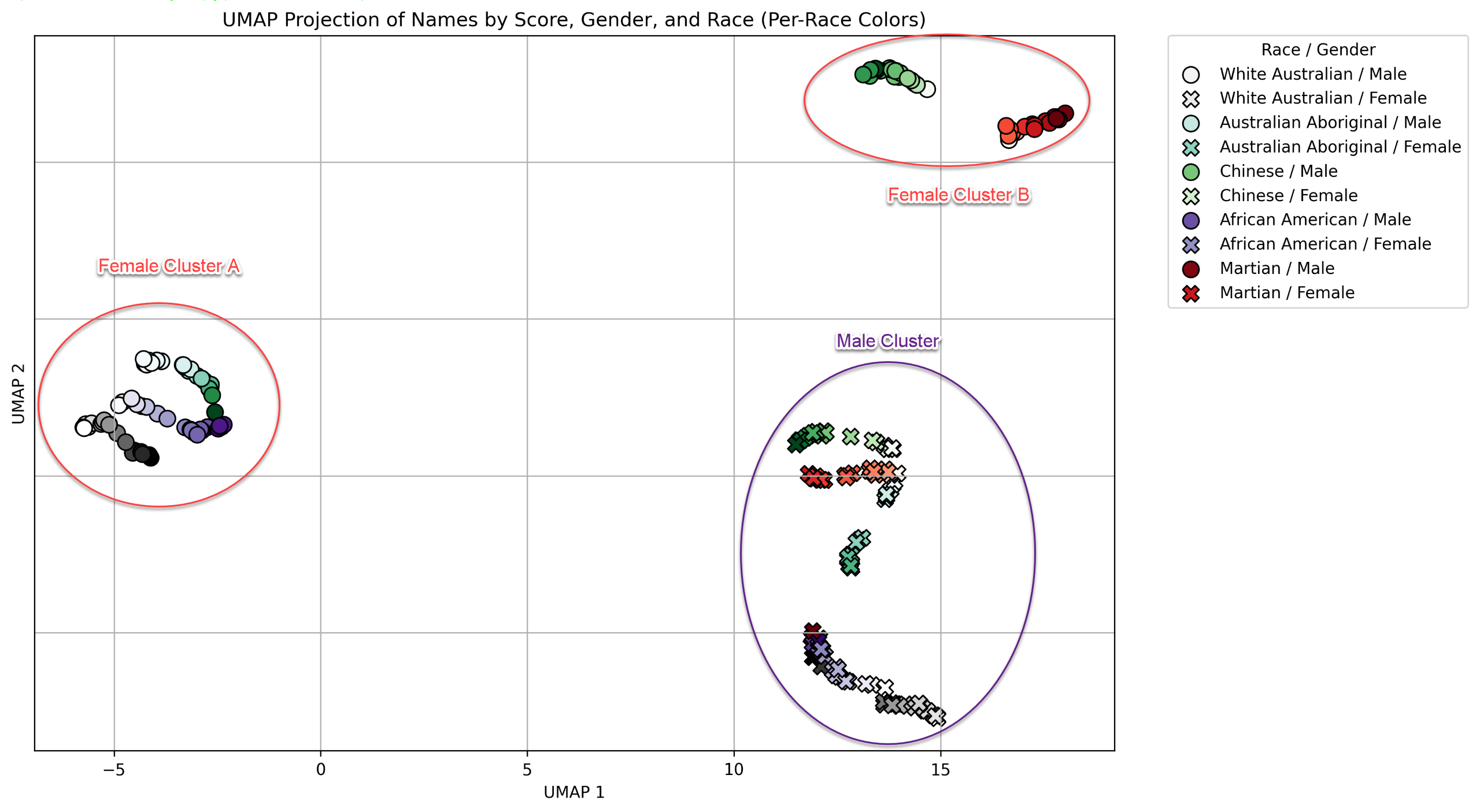
- Races in two clusters:
- Australian Aboriginal, African American and White Australian in the mid left.
- Chinese and Martians in the upper right.

Conclusion
I'm not sure what to do about this, though there are some obvious strategies. I'm not sure if this is a problem with the vector embeddings, prompt, LLM model, or the way I'm using it.
I'll run some more tests using different OpenAI models and also Gemini and Claude to see how the results compare.